The real meaning of CI (Continuous Integration)
CI stands for Continuous Integration: the term usually refers to a series of tools that execute jobs whenever a developer pushes code.
The real meaning of the term is in the actual words: Continuous Integration means to integrate continuously

Continuous Integration is the practice of merging all developers working copies to the main branch several times a day.
If you are working on a legacy software project, this definition seems complete madness: “Merging to the main branch several times a day? I’m lucky if my feature branch will arrive in the main branch in 2 months!"
This is why Continuous Integration can’t be applied without a suitable branching methodology and automated tools that ensure the quality of the work.
Branching methodologies
A branching methodology defines a set of rules developers use to create and merge branches on a version control system. If we want to Continuously Integrate, we must choose an appropriate branching methodology.
GitFlow
GitFlow is a successful branching methodology introduced in 2010. This methodology is based on two always-present branches:
main- Production-ready code.develop- The integration branch where all the development code is merged.
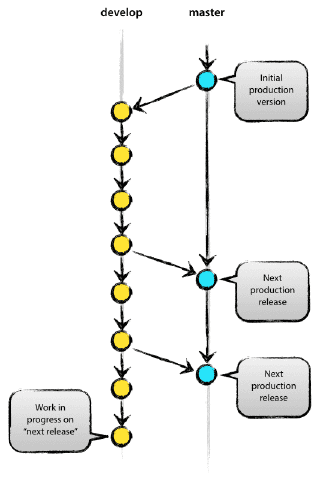
There are also other supporting branches:
featurebranchesreleasebrancheshotfixbranches
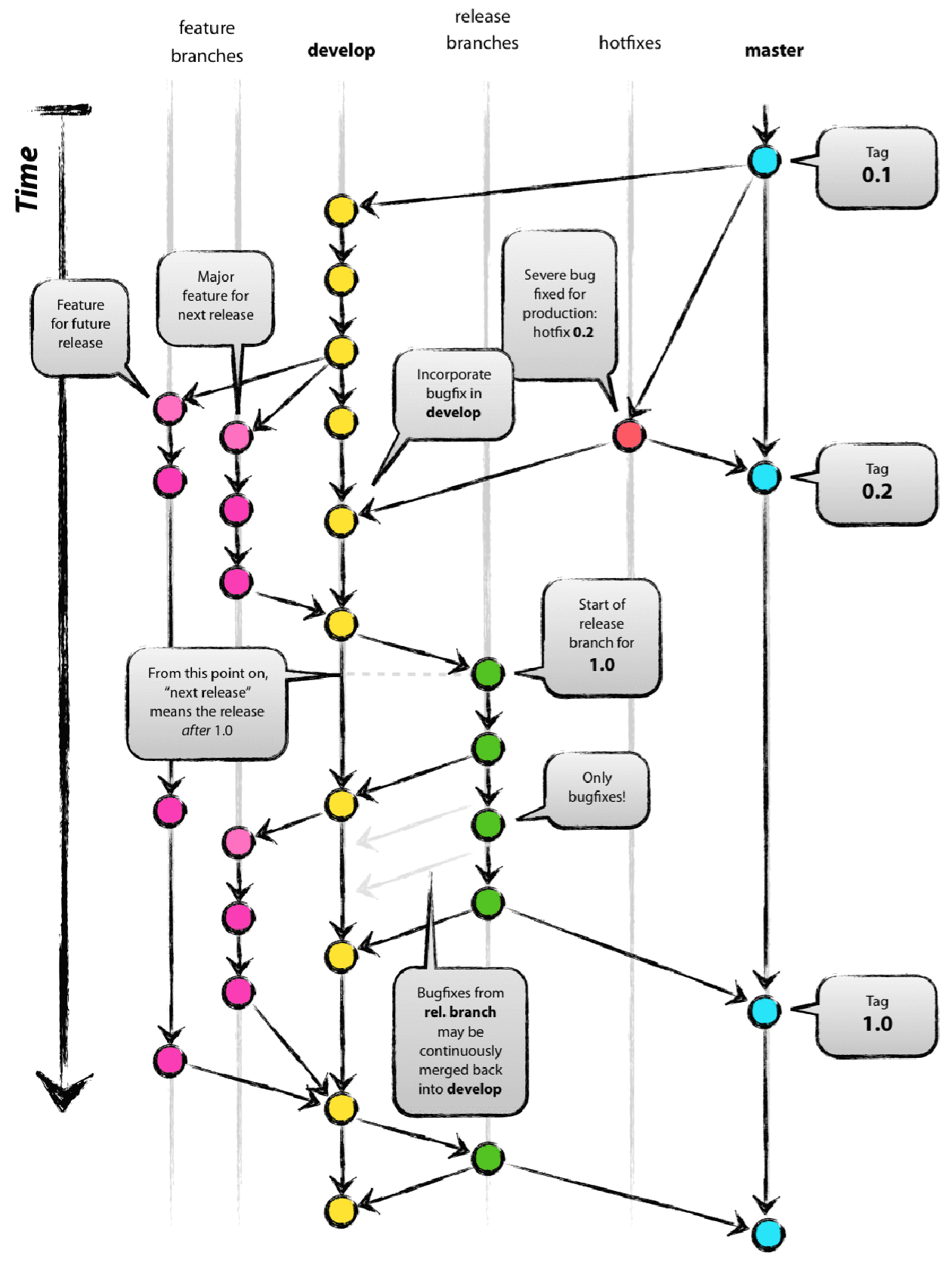
The lifecycle of a feature could be something like that:
- A
featurebranch is created fromdevelop. - A developer works on the
featurebranch for several days. - When the work is completed, the
featurebranch is merged back intodevelop. - Meanwhile, the
developbranch received other commits. - Before merging into
main, the work has to be thoroughly tested and verified. Areleasebranch is created fromdevelopto finalise the work. - The
releasebranch is thoroughly tested and fixed with other commits. - When the
releasebranch is ready, it’s finally merged intomain.
As you can see, this is the opposite of Continuos Integration. A developer’s work is not integrated continuously into the main branch, but it’s only integrated at the end of a release. This could mean it will be integrated after weeks (if you are lucky) or months.
GitHub Flow
A branching methodology that better supports Continuous Integration is the GitHub Flow.
This methodology is based on one main branch containing the production-ready code. From this branch, all the feature branches are created and merged directly into the main branch when they respect the Definition of Done.
This branching methodology allows us to continuously integrate into the main branch without all the ceremonies of the GitFlow model.
Automated Tools
Using a suitable branching methodology is only the first step: continuously merging the work on the main branch without safeguards will result in continuous disaster.
Those safeguards can be implemented using automated tools:
- Build
- Test (Unit, Integration, End-to-End)
- Code Quality
- Automatic Deploy
A fundamental aspect of CI is that those automated tools are executed for every commit, and only the commits that succeed to all the automated jobs can be merged to the main branch: This way, we can avoid continuous disaster and only merge things that don’t break the main branch.
This is why the term CI is usually associated with those automated tools: without them is nearly impossible to integrate into the main branch continuously.
Transition to CI
Legacy projects without all those automated integrations usually use the GitFlow branching methodology: the redundant branches give a buffer to test and stabilise releases while the development work is continued on other branches.
If we want to transition to a Continuous Integration model, the first step is to add automated tools to every commit to guarantee the quality of the main branch:
- The first tool to integrate is always the build to guarantee that we don’t disrupt the work of the developers by having a main branch that doesn’t compile.
- Then, we can start adding unit tests on the core part of the projects.
- Finally, we can add automatic deploys to remove all the manual procedures used for deploys.
After integrating those tools, migrating to a better branching model will be painless, reducing the Lead Time of all the work.
AranciaMeetup #02 - Gli Strumentopoli Misteriosi del Devops
My presentation (in italian) about DevOps tools is live on YouTube: https://www.youtube.com/watch?v=FkZwbnJjx6k
The slides:
Presenting Arancia Meetup
I’m happy to announce that I presented the first ‘AranciaMeetup’ on YouTube!
This initiative was conceived at Arancia-ICT some months ago: The initial idea was to create a group of technological meetings at Palermo because, unlike the rest of Italy, meetups here are nonexistent. We started to organize the first physical meetup, but then Covid-19 happened, and we had to cancel everything.
We took the opportunity and changed the meeting format to streaming events on Zoom: we allowed colleagues to share their experiences on technologies, tools and methodologies used inside various areas of the company.
After experimenting with this new way of doing internal formation, we were finally ready to start the first public meetup on YouTube!
Here’s the video in Italian:
DevOps Questo Sconosciuto
My talk about DevOps is now live on YouTube!
I received lot of questions during the live session and hadn’t enough time to answer to everyone.
The talk is in Italian and you can watch the video from here:
https://www.youtube.com/watch?v=KY1xlmlS5Zs
Contents:
- History of Software methodologies
- DevOps and definitions
- The Three Ways: Flow, Feedback and Continuous Learning ed Experimentation
- Definition of Done
- Deployment Pipeline
- Conclusions
The slides:
Some of the feedback I received:
Spiegare in modo completo ed equilibrato cos'è l'approccio #DevOps, che benefici comporta 🚀 e come introdurlo in azienda: @dzamir c'è riuscito 👏, con l'aiuto di #GDGCloud Milano💪 e di tante domande interessanti. Ora diventa ottimo materiale di riferimento🔖: grazie! 👍 https://t.co/AYaeDOePeF
— Lorenzo Gallucci | @log2@mastodon.uno (@log_two) May 6, 2020
 (from https://www.meetup.com/it-IT/GDG-Cloud-Milano/events/270361353/)
(from https://www.meetup.com/it-IT/GDG-Cloud-Milano/events/270361353/)
My Upcoming DevOps Talk (in Italian)
To all my italian friends:
Tuesday 5 May I will present a talk about DevOps!
I will explain why this is the best methodology to develop products, the origins of the movement, the “Three Ways” and how to start applying these abstract concepts concretely.
https://www.meetup.com/it-IT/GDG-Cloud-Milano/events/270361353
CPU Usage: Android Studio vs Xcode
CPU usage of compiling a native app:
— Davide Di Stefano (@dzamir) December 12, 2019
1) XCode compiling Objective-C.
2) Android Studio compiling Java.
The graph is similar in all 8 cores, so I just posted the screenshot of one core. pic.twitter.com/07eLpiAUTJ
WeightWidget Open Beta
The public beta of my new app, WeightWidget, is finally available! 🥳
— Davide Di Stefano (@dzamir) August 25, 2019
Join from this link!
👉 https://t.co/th5qLgmSA7 👈
The app is the fastest way to track your weight, directly from a Widget. pic.twitter.com/sSjPAaUd1e
Web Frontend testing strategies with Cypress
A great technology that surpass Selenium in every possible way
In the past, I tried more than once to automate website testing using Selenium, but I always had to abandon the idea because I found the tests hard to write and the documentation unclear on how to start.
This finally changed recently with Cypress.
Cypress has an excellent foundation, and it’s not based on Selenium core technologies: instead, it’s a new project based on Chromium foundations.
Cypress tests use Javascript and testing frameworks like Mocha, Chai and Sinon. More information here. If you already used testing frameworks on JS, you are basically at home.
Separate test logic from implementation details
One of the biggest problems of Frontend Testing is that, as time passes, tests start to break up because the html, js and css changes, and the test selectors and logic start breaking up.
My suggestion is to split the work this way:
- a support class that implements all the asserts, the logic, and works with selectors
- an integration class that only calls the method from the support class to do all the work.
For example, the integration.js file will contain high-level functions like these:
it('Save Post', function () {
var data = {
title: 'New Post',
text: 'Lorem Ipsum'
}
// login with the backoffice user and go to the new post
Post.loginAndGoToNewPost('backoffice')
// sets the data in the form
Post.setPostData(data)
// assert the data contained in the unsaved form
Post.assertPostData(data)
// saves the post and retrieves the id
var id = Post.savePost()
// go to the post detail
Post.goToPost(id)
// assert the data contained in the post is the same we wrote
Post.assertPostData(data)
})
The support post.js file will contain all the low-level functions to work with a post.
Login
This point it’s explained at length in Cypress documentation at this page.
Containerize the application
The first step I take when integrating frontend testing in a project is to containerize the project with Docker. This way, I only need a docker-compose up command to start the web application with an empty database.
Database should be as empty as possible
The database should also be emptied of all the data. I usually leave a few users and very little data to assert.
For example, if I have three categories of users, the database should contain one user for each role, and I save this data in a fixture:
users.json
{
"backoffice": {
"username": "backoffice",
"password": "backoffice001",
"name": "Back",
"surname": "Office"
},
"frontoffice": {
"username": "frontoffice",
"password": "frontoffice001",
"name": "Back",
"surname": "Office"
},
"user": {
"username": "user",
"password": "user001",
"name": "Mario",
"surname": "Rossi"
},
}
Now, whenever I need to run a test with different users/roles, I can do something like that:
describe('Home page: ' + userType, function () {
beforeEach(function () {
// prepare fixture for all tests
cy.fixture('users').as('users')
});
// iterate between all roles
['backoffice', 'frontoffice', 'user'].forEach((userType) => {
context('User type: ' + userType, function () {
it('Name and surname should be equal to the logged in user', function () {
// Custom command that manages the login
cy.login(this.users[userType].username, this.users[userType].password)
// Visit home page
cy.visit('/')
// UI should reflect this user being logged in
cy.get('#logged-user-name').should('contain', this.users[userType].name)
cy.get('#logged-user-surname').should('have.value', this.users[userType].surname)
})
})
})
})
Tests should never depend on previous tests
The concept is valid for all testing frameworks, but it’s important to reiterate it: A test should never depend on the result of a previous test.
For example, a test that needs to test the editing of a post shouldn’t depend on a post created from a previous test, but it should create a new post and edit it.
The process can seem tedious, but it’s crucial that every test can be executed in isolation. If your project permits it, you can use API calls to prepare and create the content needed for the specific tests.
Run the frontend tests for each commit
Frontend testing is usually slower than Unit tests, and in a Continuous Integration context, they are harder to integrate because they slow the build pipeline a lot. I also think it’s wrong to execute them only before a deploy because, in frontend testing, it’s essential to continuously find and immediately fix the regressions.
My general suggestion is to run the tests at each commit
If your CI setup doesn’t permit this, consider running the regression testing nightly on the latest ‘good’ build present in the system.
Tests must be 100% reproducible
Tests must be written in a way that, no matter how many times you repeat them, they always return the same result. This is one of the most critical part of writing tests in general, and it’s more important in Frontend Testing because they are much slower to execute and debug than Unit Testing and Integration Testing.
Imagine this scenario:
The Frontend Testing finds a couple of regressions, and your team starts analyzing the problem; after hours of hard work, they discover that the problem wasn’t in the source code but in the test code: The tests ‘randomly’ fail because they are not coded correctly. After this happens a couple of times, your team slowly starts to ignore all frontend testing regressions and also stops updating and writing them.
This is why it’s really important to start with a small but excellent test suite that will never fail for ‘random’ causes or timeouts.
After the team understands how to build top-notch tests, the test suite can be expanded and cover more cases.
Like many programming things, the expansion is usually exponential: The first couple of weeks are spent working on a basic test suite and the foundation classes that drives them, but after that phase, the test suite can expand faster.
When in doubt, check the documentation
Cypress technical documentation is excellent, and I highly suggest to read all the introductory articles; they are full of tips and high-level suggestions on how to structure your test suite.
Posting Minecraft login events to Telegram
My friends and I wanted to be notified whenever someone logins or logouts from the Minecraft server I host.
I studied a lot of overly complicated solutions until I thought of the easiest way to implement it: continuously read the Minecraft log, search for the ‘logged in’ or ‘logged out’ keywords and make an API call when there’s a result.
Translated in simplified Unix commands:
tail -F logfile | grep ‘login’ | curl api.telegram.org
The API call is made to a Telegram bot that sends the message to a group chat.
I started working from the script from this blog post and edited it a bit:
#!/bin/bash
tail -n0 -F /home/dzamir/minecraft-docker/logs/latest.log | while read LINE; do
(echo "$LINE" | grep -e "logged in" -e "left the game") && curl -X POST \
https://api.telegram.org/bot<insert-your-bot-token>/sendMessage \
-H 'Accept: */*' \
-H 'Cache-Control: no-cache' \
-H 'Connection: keep-alive' \
-H 'Host: api.telegram.org' \
-F chat_id=<insert-chat-id> \
-F text="$LINE";
done
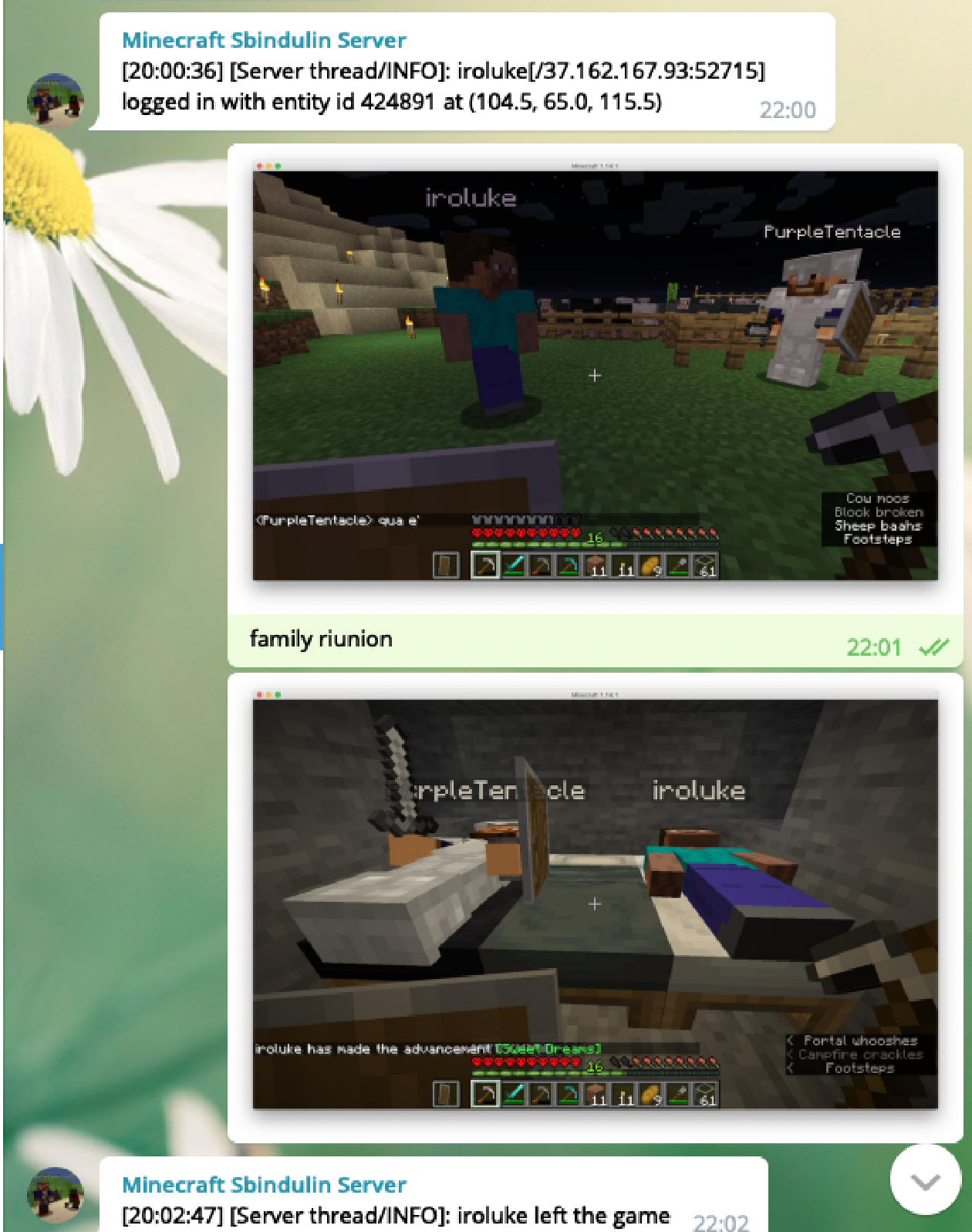
The script can be improved by filtering only the valuable data from the log messages or posting to other platforms (e.g. Slack).
Hello World
Hello World, I’m Davide Di Stefano.
I’m a software engineer with plenty of mobile Development experience.
On this website, I’ll talk about my projects, experience, ideas and rants.